
Setting up a BCP
Insight from HR Party of One.
In simple terms, BCP is the game plan that keeps business operations humming along during a disaster. Whether it’s a power outage, system failure, or something as drastic as an earthquake, BCP ensures that business interruptions are kept to a minimum.
And Disaster Recovery Planning (DRP)? That’s the sidekick focused on getting IT back on its feet. DRP is actually a part of BCP, the muscle that restores technology services quickly.
Let’s break down some actionable steps for building a rock-solid BCP.
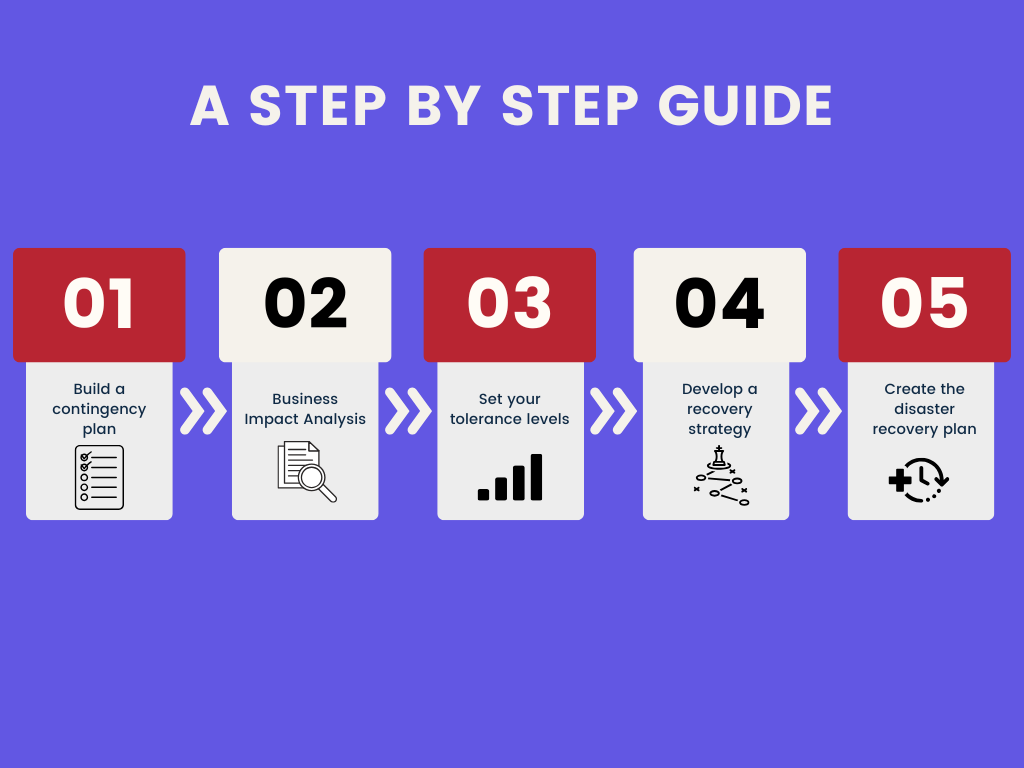
Step 1: Build a Contingency Policy
Start with the basics. You need a contingency policy—this is the rulebook everyone in the organization will follow in a crisis. Make sure top management is involved, and get their statements of support, which can also set boundaries like which regions the plan applies to. This policy is the framework that lets everyone know you’re serious about keeping things running no matter what.
Pro tip: The policy doesn’t have to be fancy, but it needs to be clear. Make sure it includes management’s commitment to keeping resources available and the services rolling.
Step 2: Business Impact Analysis (BIA)
The BIA is all about figuring out what’s mission-critical and what can wait. It’s like a triage system—you’re deciding which services and assets absolutely cannot go down and for how long they can stay offline before the costs become painful.
Here’s the BIA Process:
List all business processes: Identify your revenue-generating processes and who owns them.
Estimate the revenue impact: Calculate the potential losses if each process goes down.
Set up meetings with key players: Understand the importance of each process directly from the business owners.
Prioritize based on impact: Decide which processes to recover first, like who needs a hot site (instant switch-over) and who can make do with a warm site (recovery within a few hours).
Step 3: Set Your Tolerance Levels (MTD, RTO)
Once you know the critical processes, you’ll need to pin down Maximum Tolerable Downtime (MTD) and Recovery Time Objectives (RTO) for each one.
MTD is the absolute maximum time a service can be down without causing major issues.
RTO is how quickly you aim to recover each service. Say your MTD for a process is 30 minutes; your RTO should be something achievable within that timeframe, like 25 minutes.
Step 4: Develop a Recovery Strategy
Now you’ve got to create a recovery strategy based on the BIA findings and tolerance levels. This is where you make the big decisions:
Which sites or servers will be redundant?
Who gets priority if two services are down at once?
What’s the backup plan for power or internet failures?
Present alternative solutions too! Sometimes, a full backup server might be overkill. Offer a more cost-effective option like cloud storage or data redundancy that could bring down the costs significantly.
Step 5: Create the Disaster Recovery Plan (DRP)
Now it’s time to roll up your sleeves and outline a Disaster Recovery Plan (DRP), detailing how you’ll recover specific processes and services. The DRP should include:
Contact information for critical personnel,
Step-by-step actions to restore services,
Target times for recovery.
Test the DRP regularly and keep it updated so it’s ready when disaster strikes. The goal is to make switching from one site to another—like from your primary server in Noida to the backup in Gurgaon—a smooth, near-instantaneous process.